

Tangu uzinduzi wake wa umma miaka 10 iliyopita, Twitter imekuwa ikitumika kama jukwaa la mitandao ya kijamii kati ya marafiki, huduma ya kutuma ujumbe kwa papo kwa watumiaji wa smartphone na zana ya uendelezaji kwa mashirika na wanasiasa.
Lakini pia imekuwa chanzo muhimu cha data kwa watafiti na wanasayansi - kama mimi - ambao wanataka kusoma jinsi wanadamu wanahisi na wanafanya kazi katika mifumo tata ya kijamii.
Kwa kuchambua tweets, tumeweza kuchunguza na kukusanya data juu ya mwingiliano wa kijamii wa mamilioni ya watu "porini," nje ya majaribio ya maabara yaliyodhibitiwa.
Imewezeshwa kukuza zana za ufuatiliaji wa hisia za pamoja za idadi kubwa ya watu, pata maeneo yenye furaha zaidi nchini Merika na mengi zaidi.
Kwa hivyo, je! Twitter imekuwaje rasilimali ya kipekee kwa wanasayansi wa kijamii wa hesabu? Na imeturuhusu kugundua nini?

Zawadi kubwa ya Twitter kwa watafiti
Mnamo Julai 15, 2006, Twittr (kama ilivyojulikana wakati huo) hadharani ilizindua kama "huduma ya rununu inayosaidia vikundi vya marafiki kugongana na mawazo yasiyokuwa ya kawaida na SMS." Uwezo wa kutuma maandishi ya kikundi cha wahusika 140 bure uliwaongoza wapokeaji wengi wa mapema (mimi mwenyewe nilijumuisha) kutumia jukwaa.
Kwa wakati, idadi ya watumiaji ililipuka: kutoka milioni 20 mwaka 2009 hadi milioni 200 mwaka 2012 na milioni 310 leo. Badala ya kuwasiliana moja kwa moja na marafiki, watumiaji wangewaambia tu wafuasi wao jinsi walihisi, kujibu habari vyema au vibaya, au kupasua utani.
Kwa watafiti, zawadi kubwa zaidi ya Twitter imekuwa utoaji wa data nyingi wazi. Twitter ilikuwa moja wapo ya mitandao kuu ya kwanza ya kijamii kutoa sampuli za data kupitia kitu kinachoitwa Maingiliano ya Programu ya Maombi (APIs), ambayo huwawezesha watafiti kuuliza Twitter kwa aina maalum za tweets (kwa mfano, tweets zilizo na maneno fulani), na pia habari juu ya watumiaji .
Hii ilisababisha mlipuko wa miradi ya utafiti inayotumia data hii. Leo, utafutaji wa Google Scholar wa "Twitter" hutoa milioni sita, ikilinganishwa na milioni tano kwa "Facebook." Tofauti ni ya kushangaza sana ikizingatiwa kuwa Facebook ina takribani mara tano ya watumiaji wengi kama Twitter (na ana umri wa miaka miwili).
Sera ya data ya ukarimu ya Twitter bila shaka ilisababisha utangazaji bora wa bure kwa kampuni hiyo, kwani masomo ya kuvutia ya kisayansi yalichukuliwa na media kuu.
Kujifunza furaha na afya
Na data ya sensa ya jadi polepole na ghali kukusanya, milisho ya data wazi kama Twitter ina uwezo wa kutoa dirisha la wakati halisi kuona mabadiliko katika idadi kubwa ya watu.
Chuo Kikuu cha Vermont Maabara ya Hadithi ya Kompyuta ilianzishwa mnamo 2006 na inasoma shida katika hesabu zilizotumika, sosholojia na fizikia. Tangu 2008, Maabara ya Hadithi imekusanya mabilioni ya tweets kupitia lishe ya Twitter ya "Gardenhose", API ambayo inasambaza sampuli ya nasibu ya asilimia 10 ya tweets zote za umma kwa wakati halisi.
Nilikaa miaka mitatu kwenye Maabara ya Hadithi ya Kompyuta na nilikuwa na bahati kuwa sehemu ya masomo mengi ya kupendeza kutumia data hii. Kwa mfano, tulianzisha hedonometer ambayo hupima furaha ya Twittersphere kwa wakati halisi. Kwa kuzingatia tweets za geolocated zilizotumwa kutoka kwa simu mahiri, tuliweza ramani sehemu zenye furaha zaidi nchini Merika. Labda bila kushangaza, tulipata Hawaii kuwa jimbo lenye furaha zaidi na kuongezeka kwa divai Napa jiji lenye furaha zaidi kwa 2013.
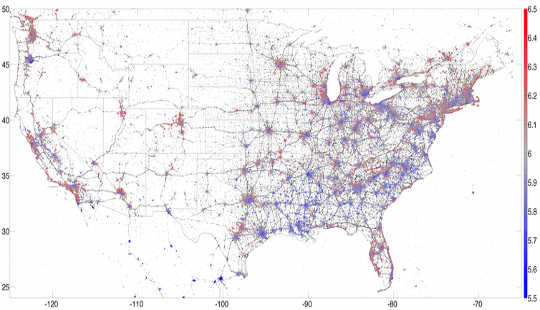 Ramani ya tweets milioni 13 za Amerika zilizo na geolocated kutoka 2013, zilizochorwa na furaha, na nyekundu ikionyesha furaha na bluu ikionyesha huzuni. PLoS ONE, Mwandishi ametoa.Masomo haya yalikuwa na matumizi ya kina: Kuhusiana na matumizi ya maneno ya Twitter na idadi ya watu kulitusaidia kuelewa mifumo ya kimsingi ya uchumi katika miji. Kwa mfano, tunaweza kuunganisha matumizi ya neno na sababu za kiafya kama unene kupita kiasi, kwa hivyo tuliunda faili ya lexicocalorimeter kupima "maudhui ya kalori" ya machapisho ya media ya kijamii. Tweets kutoka mkoa fulani ambazo zilitaja vyakula vyenye kalori nyingi ziliongeza "maudhui ya kalori" ya mkoa huo, wakati tweets ambazo zilitaja shughuli za mazoezi zilipunguza kipimo chetu. Tuligundua kuwa hatua hii rahisi inahusiana na metriki zingine za afya na ustawi. Kwa maneno mengine, tweets ziliweza kutupa picha, kwa wakati fulani kwa wakati, ya afya ya jumla ya jiji au mkoa.
Ramani ya tweets milioni 13 za Amerika zilizo na geolocated kutoka 2013, zilizochorwa na furaha, na nyekundu ikionyesha furaha na bluu ikionyesha huzuni. PLoS ONE, Mwandishi ametoa.Masomo haya yalikuwa na matumizi ya kina: Kuhusiana na matumizi ya maneno ya Twitter na idadi ya watu kulitusaidia kuelewa mifumo ya kimsingi ya uchumi katika miji. Kwa mfano, tunaweza kuunganisha matumizi ya neno na sababu za kiafya kama unene kupita kiasi, kwa hivyo tuliunda faili ya lexicocalorimeter kupima "maudhui ya kalori" ya machapisho ya media ya kijamii. Tweets kutoka mkoa fulani ambazo zilitaja vyakula vyenye kalori nyingi ziliongeza "maudhui ya kalori" ya mkoa huo, wakati tweets ambazo zilitaja shughuli za mazoezi zilipunguza kipimo chetu. Tuligundua kuwa hatua hii rahisi inahusiana na metriki zingine za afya na ustawi. Kwa maneno mengine, tweets ziliweza kutupa picha, kwa wakati fulani kwa wakati, ya afya ya jumla ya jiji au mkoa.
Kutumia utajiri wa data ya Twitter, tumeweza pia ona mitindo ya harakati za kila siku za watu kwa undani zaidi. Kuelewa mifumo ya uhamaji wa binadamu, kwa upande wake, ina uwezo wa kubadilisha mfano wa magonjwa, kufungua uwanja mpya wa magonjwa ya kidigitali.
Kwa masomo mengine, tuliangalia ikiwa wasafiri wanaonyesha furaha kubwa kwenye Twitter kuliko wale wanaokaa nyumbani (jibu: wanafanya) na ikiwa watu wenye furaha huwa wanashikamana kwenye mtandao wa kijamii (tena, wanafanya). Hakika, chanya inaonekana kuokwa katika lugha yenyewe, kwa maana kwamba tuna maneno mazuri kuliko maneno hasi. Hii haikuwa hivyo tu kwenye Twitter lakini kwa media anuwai tofauti (kwa mfano, vitabu, sinema na magazeti) na lugha.
Masomo haya - na maelfu ya wengine kama wao kutoka ulimwenguni kote - waliwezekana tu kwa Twitter.
Miaka 10 ijayo
Kwa hivyo tunaweza kutarajia kujifunza kutoka kwa Twitter kwa miaka 10 ijayo?
Baadhi ya kazi ya kufurahisha zaidi kwa sasa inajumuisha kuunganisha data ya media ya kijamii na vielelezo vya hesabu kutabiri hali za idadi ya watu kama milipuko ya magonjwa. Watafiti tayari wamefanikiwa katika kuongeza mifano ya magonjwa na data ya Twitter kutabiri mafua, haswa FluOutlook jukwaa lililotengenezwa na Chuo Kikuu cha Kaskazini mashariki na Taasisi ya Kubadilishana Sayansi.
Bado, changamoto kadhaa zinabaki. Takwimu za media ya kijamii zinakabiliwa na kiwango cha chini sana cha "ishara-kwa-kelele". Kwa maneno mengine, tweets ambazo zinafaa kwa utafiti fulani mara nyingi huzama na "kelele" isiyo na maana.
Kwa hivyo, lazima tuendelee kufahamu kile kilichoitwa "data kubwa hubris”Tunapotengeneza mbinu mpya na tusijiamini kupita kiasi kwa matokeo yetu. Imeunganishwa na hii inapaswa kuwa lengo la kutoa utabiri wa "glasi-sanduku" ya kutafsiri kutoka kwa data hizi (tofauti na utabiri wa "sanduku-nyeusi", ambayo algorithm imefichwa au haijulikani wazi).
Takwimu za media ya kijamii mara nyingi (haki) hukosolewa kwa kuwa ndogo, sampuli isiyowakilisha ya idadi kubwa ya watu. Moja ya changamoto kubwa kwa watafiti ni kujua jinsi ya kuhesabu data kama hii iliyokosekana katika mifano ya takwimu. Wakati watu zaidi wanatumia mitandao ya kijamii kila mwaka, lazima tuendelee kujaribu kujaribu upendeleo katika data hii. Kwa mfano, data bado inawakilisha watu wadogo kwa gharama ya watu wazee.
Ni baada tu ya kutengeneza njia bora za kusahihisha upendeleo watafiti wataweza kufanya utabiri kamili kutoka kwa tweets.
Kuhusu Mwandishi
Lewis Mitchell, Mhadhiri wa Hisabati Iliyotumiwa, Chuo Kikuu ya Adelaide
Makala hii ilichapishwa awali Mazungumzo. Soma awali ya makala.
Vitabu kuhusiana
at InnerSelf Market na Amazon




















